A. Reconstruction from compressedREpresentation

1. z라는 축소된 벡터를 얻는 방법을 알았다. 그렇다면 어떻게 다시 2차원의 백터로 돌아갈 수 있을까?
2. 식에서 볼 수 있다시피, 축소된 백터를 얻을 때 사용되었던 U_reduce라는 좌측 특이벡터를 이용하여, 본래 X의 근사한 값을 구할 수 있다. 이를 Construction(복원)이라 한다.
B. choosing the Number of principa componet

1. 얼마나 축소할 지 결정하기 위해서는, 축소 결과가 본래의 데이터를 얼마나 포함하고 있는지를 알아야 한다.
2. 여기서도 사용되는 비용함수의 개념, 위에서 보이는 식에서 분모를 본래정보, 분자를 축소된 정보를 이해하면 되겠다. 분자에서 차이값이 작을수록, 축소된 정보는 작아지게 된다.
3. 통상 99, 95%의 정보가 보존되어야 한다고 한다.

1. 요걸 어떻게 조금 더 쉽게 해볼까에 대한 답이 오른쪽의 공식이다. svd를 통해 만들어지는 새 개의 행렬 중 가운데의 S행렬은 특이값 행렬이다. 이 특이값 행렬응 통해서 K를 쉽게 찾을 수 있다.
2. 전체 특이값을 다 더한 겂을 분모로, K개를 선택하여 더한 특이값을 분자로 한 후 그 비율이 0.95또는 0.99가 넘으면 된다.
C. Advice for Applying PCA
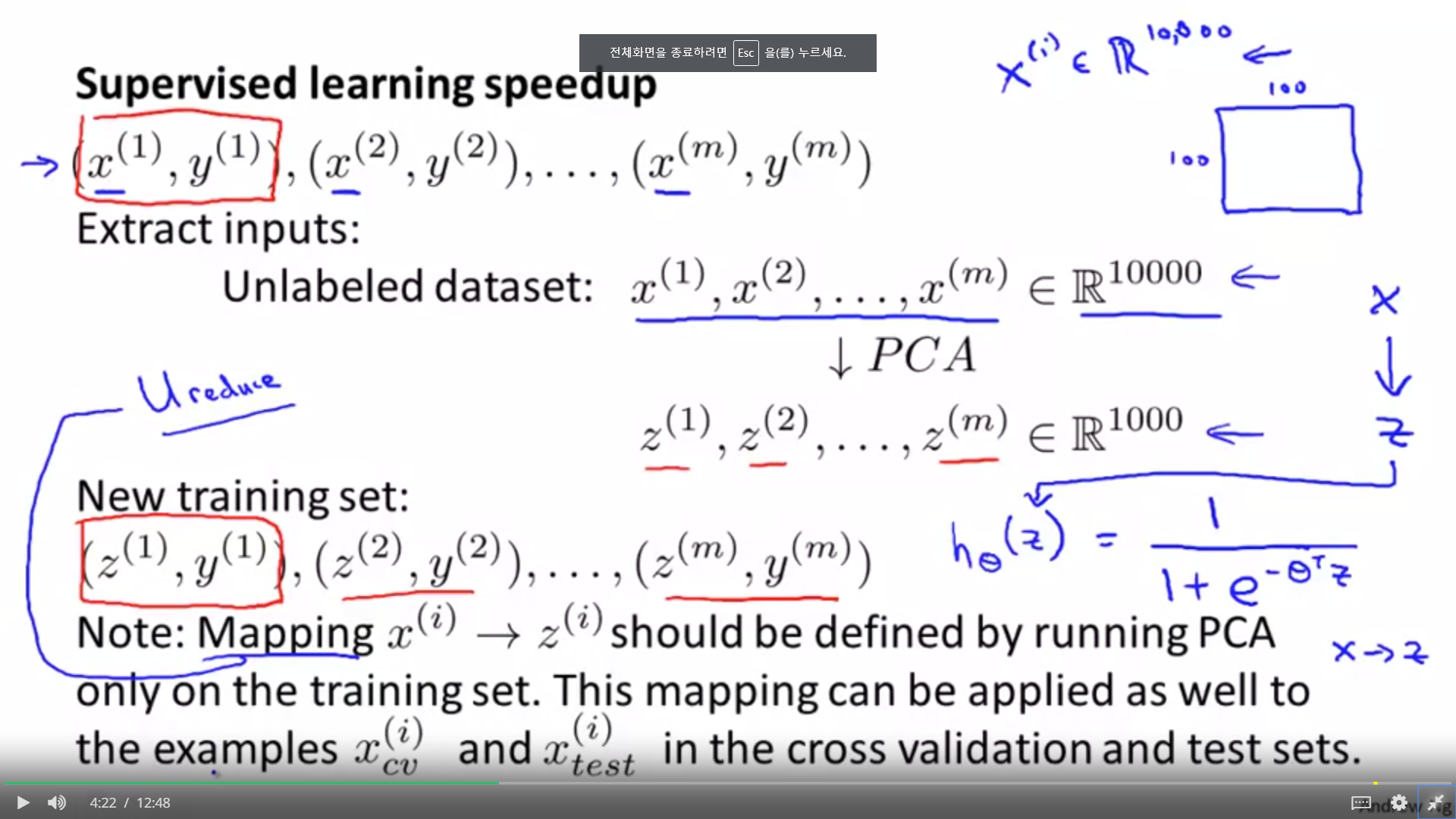
1. PCA 자체가 속도를 높이기 위해 사용되기도 하는데, 주의할 점은 차원축소에서 사용되는 축소방법이 똑같이 테스트 셋에도 적용이 되야 한다는 것이다. 그렇기 떄문에 Mapping(U_reduce)는 트레인 셋에 의해서만 정의되어야 한다.

2. PCA를 오버피팅을 피하기 위해서 사용하는 것은 잘못된 것이다. 적은 피쳐일 수록, 오버피팅이 덜 되긴 하지만, PCA 자체는 속도와 시각화에 집중된 도구이다. 오버피팅을 피하기 위해서 차라리 정규화 방법을 사용하자.

1. PCA를 사용하기 전에 반드시 본래의 데이터로 실험을 진행해보자. 이것이 잘 작동하지 않을 떄 PCA라는 방법을 사용해보자.
'2019년 혁신성장 청년인재 집중양성(빅데이터) > [COURSERA] Machine Learning Stanford Uni' 카테고리의 다른 글
| [week9] Building an Anomaly Detection System (0) | 2019.11.07 |
|---|---|
| [week9] Densitiy Estimation (0) | 2019.11.06 |
| [week8] Principal Component Analysis (0) | 2019.11.03 |
| [week8] Data Compression (0) | 2019.11.03 |
| [week8] Clustering (0) | 2019.11.03 |



