* gut feeling 직감
Deciding What to try Next
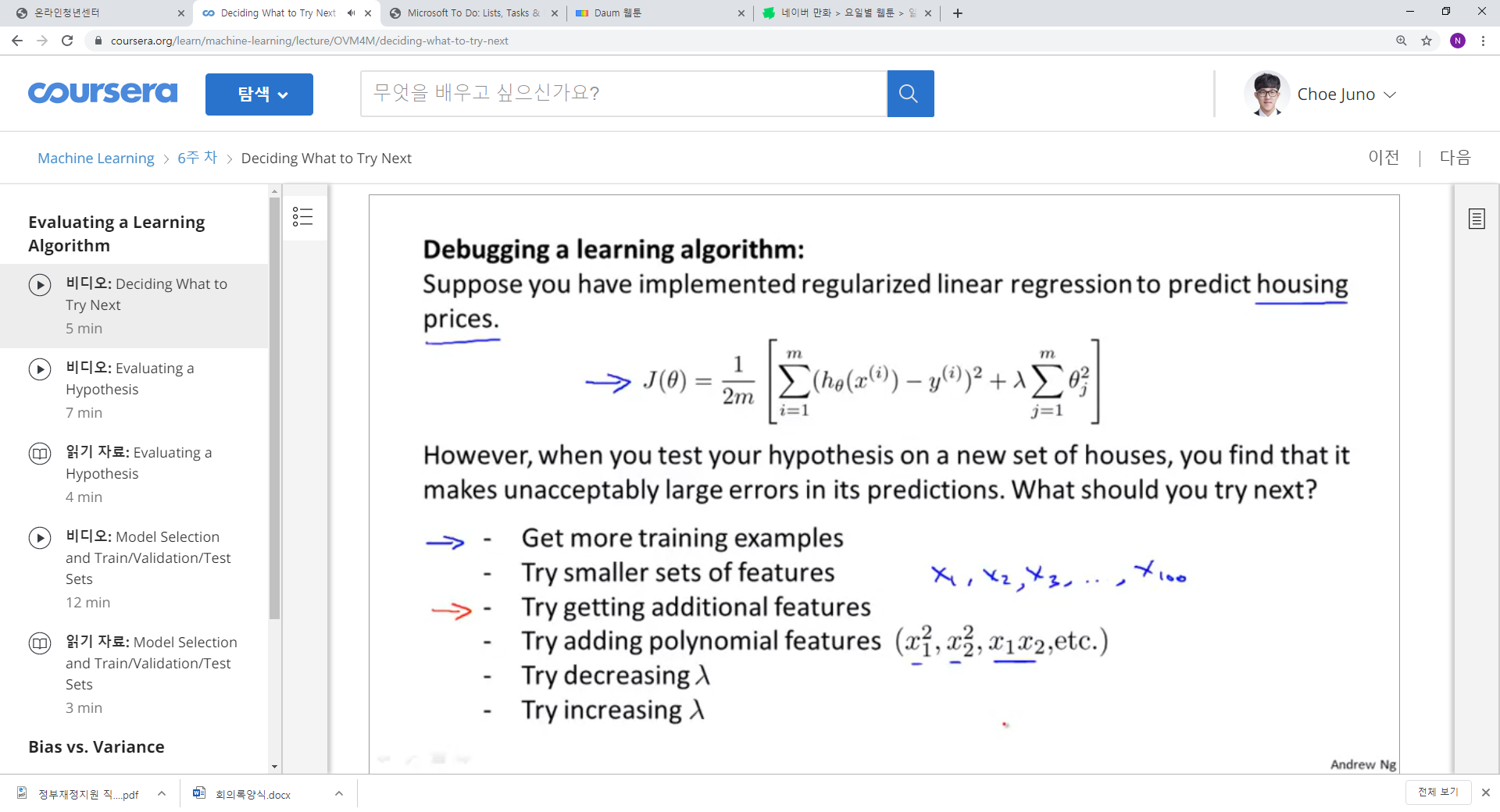
1. 예측을 했다~ 결과가 거지 같다~ 어떻게 할까~
2. 1) 트레인 수를 늘린다. 2) 피쳐를 덜 사용한다. 3) 추가적인 피쳐를 사용한다. 4) 폴리노미얼한 피쳐를 더한다. 5) 러닝 레이트를 감소 시키거나 증가시킨다.
3. 보통 사람들은 트레인 데이터를 더 모으거나, 피쳐를 더 모으거나, 아니면 직감에 의존해서 여러가지 파라미터를 수정한다.
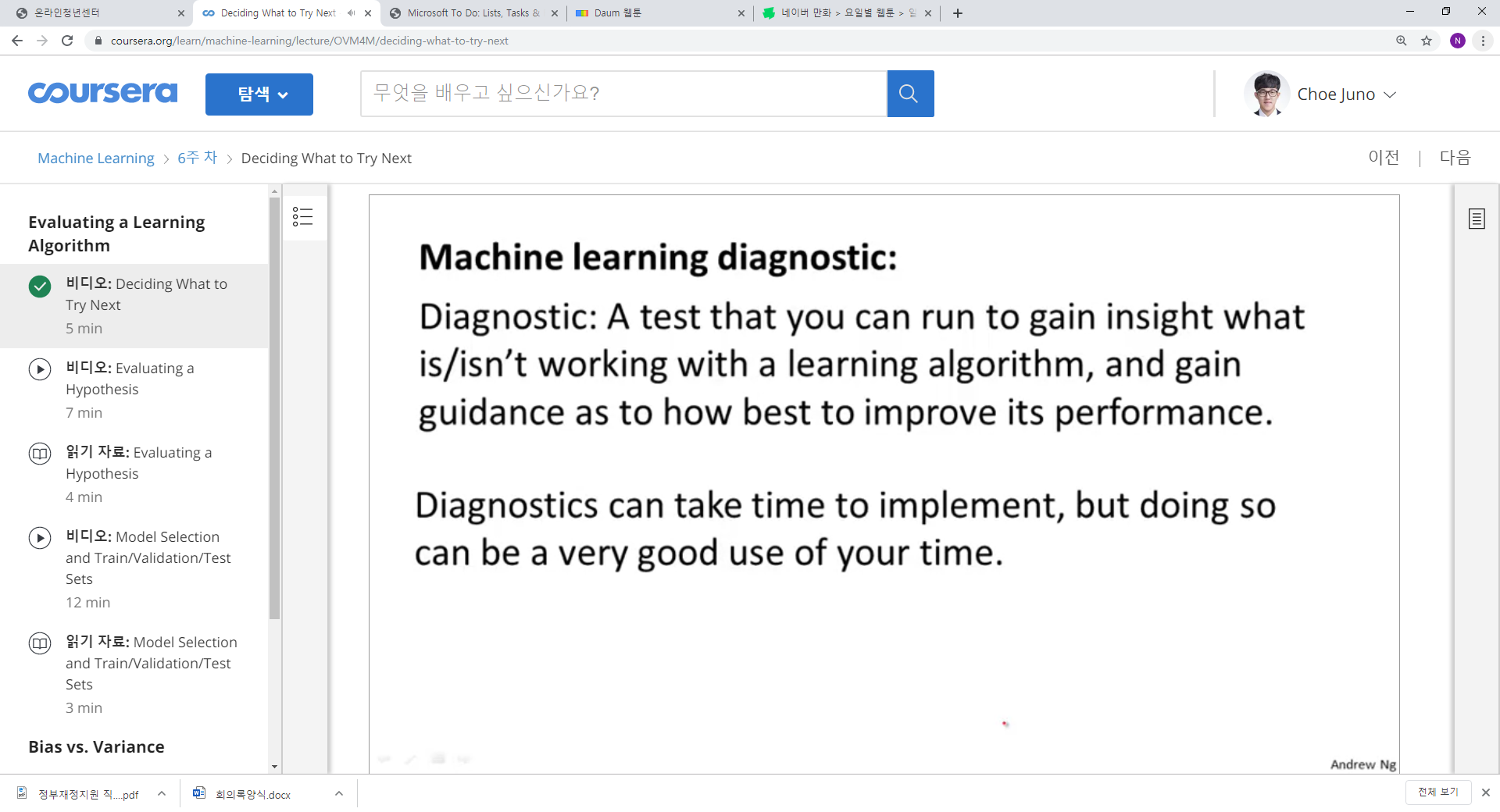
1. 그러지 말라! 감에 의존하지 말라! 진단을 해라!
2. 진단을 통해 알고리즘으로 부터의 통찰을 얻을 수 있고, 어떤 파라미터를 조정해야 하는지에 대한 정보를 얻을 수 있다.
3. 진단은 시간이 들 수 있으나, 감에 의존한 시간 보다는 훨씬 좋다.
Evaluating Hypothesis
1. 가설은 트레이닝 샘플에 대해서는 낮은 에러를 가질 수 있지만, 부정확할 수 있다. 왜냐하면 그것이 오버피팅 되어 있을 수 있기 대문이다. 즉, 가설을 평가하기 위해서는 테스트 셈플이 필요하다는 것이다.
2. 간단하다. 트레인 셈플로 비용함수가 최소가 되는 가설을 찾고, 그 가설을 이용해 테스트에 대한 비용함수를 계산하는 것이다.
3. 선형회귀의 경우, 비용함수를 그대로 사용할 수 있고, 로지스틱 회귀의 경우 테스트의 y값과 예측값이 틀린 곳을 1로 배정한 후, 그 값을 모두 더한 뒤, 총 테스트 수로 나누어 주면 된다.
Evaluating a Learning Algoritms
1.트레인 셋에 잘 맞는 다고 좋은 가설이 아니다. 오버피팅 된 것일 수 있기 때문에, 어찌 되었는 트레인의 에러는 테스트와 베일데이션 세보다 낮을 수밖에 없다.
2. 먼저 가능한 모델을 상정하고, 어떤 모델이 가장 좋은 모델인지 확인하기 위해, 각 모델의 베일데이션셋에 대한 에러 값을 조사한다. 그후, 그 모델을 이용하여 테스트 셋에 대한 에러 값을 확인한다.
3. 일반적으로 트레인 60%, 베리데이션 20%, 테스트 20%이다.
'2019년 혁신성장 청년인재 집중양성(빅데이터) > [COURSERA] Machine Learning Stanford Uni' 카테고리의 다른 글
| [week6] Building a Spam Clasifier (0) | 2019.10.10 |
|---|---|
| [week6] Evalutating a Learning Algorithm (0) | 2019.10.10 |
| [week5] Neural Networks : Learning, Cost Function and Backpropagation (0) | 2019.10.03 |
| [week4] Applications (0) | 2019.10.03 |
| [week4] Neural Network (0) | 2019.09.30 |



