A. Bias vs. Variance
1.기계학습에 뭔가 문제가 있다면, 그 문제는 bias(선입관) 또는 variance(분산) 둘 중 하나 떄문이다.
2 이 선입관과 분산성을 구분해줄 필요가 있다.
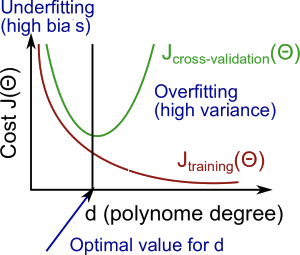
3. 모델이 선입견이 심하다면 설명력이 약해진다(underfitting). 모델이 높은 가변성을 가지면 이는 트레인 데이터에 과도하게 아부하는 꼴이 된다. 선입견이 강해지면 트레인에 대한 설명력이 강해지는 대신, 테스트에 대한 설명력은 약해지게 되는 것이다. 적절한 타협이 필요하다.
4. 항수가 높아질수록 오류는 줄어드는 경향이 있다, 동시에 어떤 지점까지 테스트의 오차 또한 줄어들며, 이 지점이 지나면 볼록한 커브를 형상하며 다시 증가하게 된다.
B. Regularization and Bias/Variance
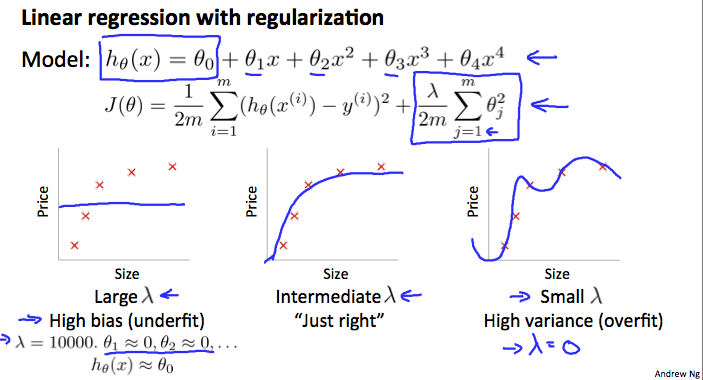
1. 람다가 크게 되면, 세타는 0에 수렴하고 트레인과 테스트 모두에 대하여 설명력은 약해진다.
2. 람다가 작게 되면, 세타는 트레인에 대한 설명력이 강하며, 테스트에 대한 설명력은 약해진다.
3. 그러니 일단, 여러 가능성에 대해 상정 해보고, 가장 적절한 세타와 람다의 조합을 택해야 한다.
C. Learning Curves
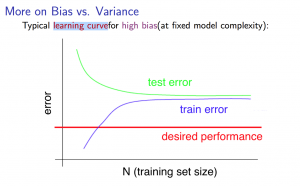
1. 트레인 데이터가 적다면, 그로부터 만들어진 모델의 비용함수는 거의 0에 수렴한다.
2. 트레인 데이터의 수가 많아질수록, 비용함수는 증가한다.
3. 비용함수는 특정 트레인 개수 이후 안정기에 진입한다.(plateau). 왜냐하면 트레인 수가 늘어날수록, 모델은 정교해지며, 오차도 줄어들게 되기 떄문이다.
4. 적은 수의 트레인 사이즈는 트레인의 비용함수가 작고, 테스트의 비용함숙 높다
5. 많은 수의 트레인 사이즈는 트레인의 비용함수와 테스트의 비용함수가 결국은 수렴하게 된다.
6. 높은 편향성에의 의해서 알고리즘이 제대로 작동하지 않는다면, 더 많은 수의 트레인이 필요하
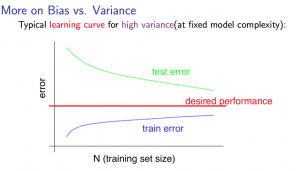
1. 높은 가변도를 지닌 모델의 경우, 트레인의 수가 적다면, 트레인의 오차는 적은 반면, 테스트의 오차는 클 것이다.
2. 또 테스트의 숫자가 충분히 커졌을 떄에도, 트레인과 테스트의 오차는 분명하게 관찰될 것이다.
3. 모델이 높은 가변성, 분산성에 의해 잘 작동되지 않는다면 더 많은 트레인 샘플을 이용하는 것이 좋다.
*bias는 모델의 자아가 너무 강하기 떄문에, 트레인과 테스트 모두 비용이 높아진다. variance는 모델이 오히려 자신의의 정체성을 포기하고 트레인데이터로서 자아를 형성하기에 트레인에 대해서는 오버피팅하지만, 테스트에 대해서는 설명할 수 없게 되는 것이다.
D. Decideing What to Do Next Revisited
1. 높은 가변성(오버피팅)되어 있다면, 트레인 수를 늘리거나, 더 적은 수의 피쳐를 사용하거나, 람다를 올린다.
2. 높은 편향성(언더피팅)되어 있다면, 피쳐를 더하거나, 다항식을 쓰거나, 람다를 줄인다.
3. 신경망의 경우, 적은 수의 파라미터는 언더피팅 하기 쉬우며, 비용적으로 저렴하다.
4. 많은 파라미터가 있는 큰신경망의 경우 오버피팅의 가능성이 있고, 비용적으로 비싸다. 이 경우에 람다의 크기를 높일 수 있다.
5. 단일 신경망을 이용하는 것은 좋은 기본 값이며, 낮은 차수의 다항식은 높은 bias와 낮은 variance를 가지며, 이 경우 모델은 잘 맞지 않는다. 높은 차수의 다항식의 경우 트레인 데이터에는 잘 맞으나, 테스트 데이터에는 잘 맞지 않는다. 이것은 낮은 bias와 높은 variance를 가진다.
6. 실제에서, 우리는 그 사이에서 모델을 선택해야 한다.
'2019년 혁신성장 청년인재 집중양성(빅데이터) > [COURSERA] Machine Learning Stanford Uni' 카테고리의 다른 글
| [week6] Handling Skewed Data (0) | 2019.10.11 |
|---|---|
| [week6] Building a Spam Clasifier (0) | 2019.10.10 |
| [week6] Evaluating a Learning Algoritm (0) | 2019.10.06 |
| [week5] Neural Networks : Learning, Cost Function and Backpropagation (0) | 2019.10.03 |
| [week4] Applications (0) | 2019.10.03 |



