A. Kernels 1

1. 선형적으로 분류가 불가능한 데이터에 대해서, 다항식을 통해 접근 할 수 있지만, 다항식은 비용적으로 비싸다. 그래서 나왔던 것이 ANN이었다. SVM에서는 새로운 피쳐 f를 생성하여 계산의 복잡함을 해결한다.

1. 커널이라는 방법은 유사도라는 새로운 피쳐를 생성하는 것이다. 유사도는 특정한 랜드마크와 얼마나 가까운지로 결정이 된다. 즉, 모든 피쳐는 랜드마크와 가까움의 정도로 0~1사이의 값으로 변환되는 것이다.

1. f1이라는 새로운 피쳐는 랜드마크 1에서 가깝다면 1에 근사하고, 멀다면 0에 근사한다.
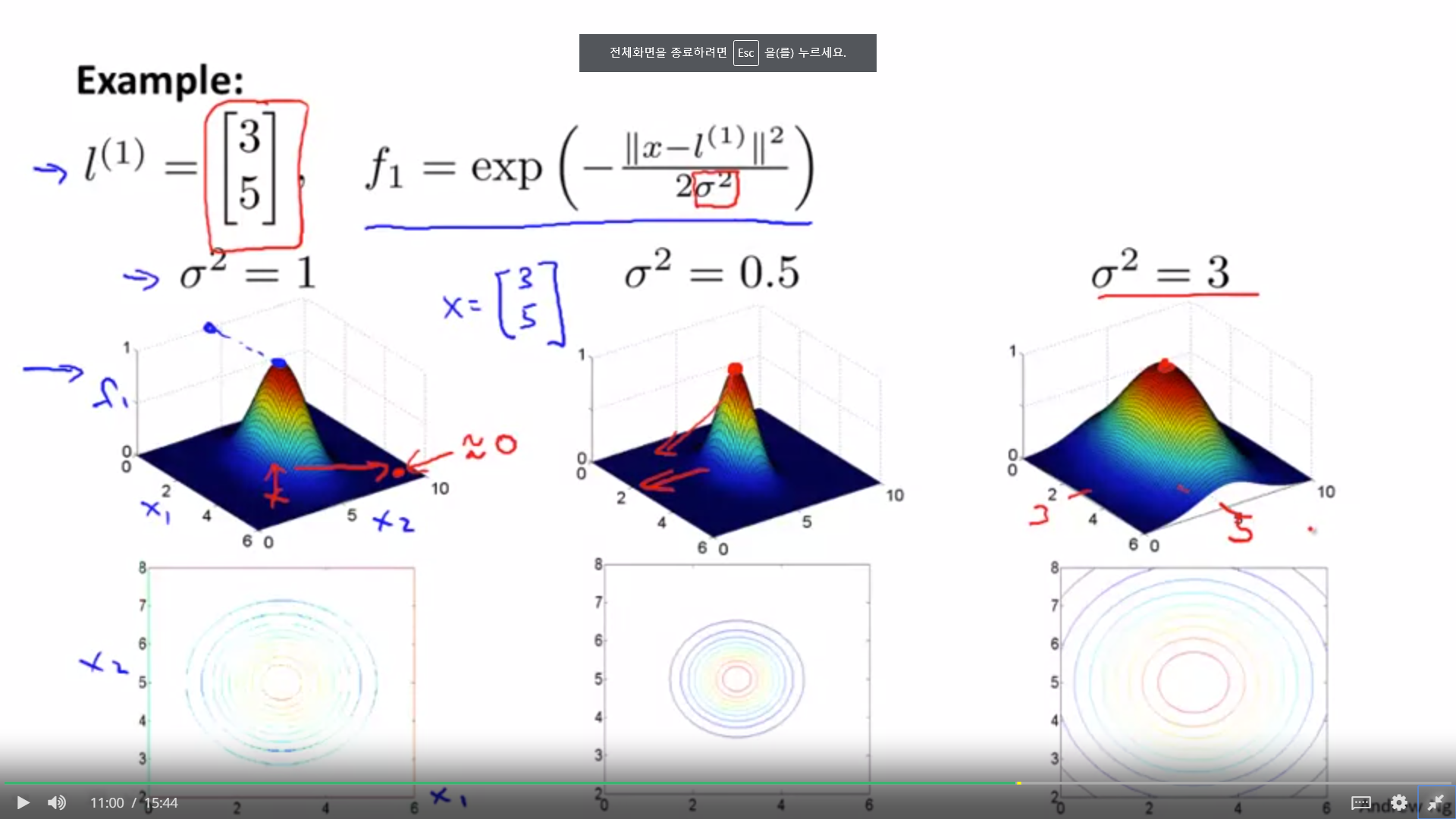
1. 이때, f1을 만드는 데 사용되는 시그마가 커질수록, 더욱 완만하게 f1의 값은 변하게 된다. 이러한 분포를 보이는 f를 가우시안 커널이라고 한다. 아마 표준편차인것으로 보이는데, 표준편차가 커질수록, 완만한 곡선을 뛰게 된다.

1. x의 피쳐들이 커널을 통해서 변환되면, 랜드마크 주변의 분포 형태로 비선형적인 분류가 가능하게 된다.
B. Kernel 2

1. 그렇다면 커널의 랜드마크를 어떻게 설정하느냐? 모든 관측치 x를 모두, 즉 m개의 랜드마크를 만들고, 각각의 x와 다른 x 사이의 유사도를 뽑아, m개의 새로운 feature를 만드는 것이다.
2. 그렇다면 n개의 피쳐를 가졌다고 하더라도, 새로운 피쳐는 다른 관측치와의 유사도이기 때문에 결국 m개의 피쳐가 생겨버리게 되는 것이다.

1. 커널에 의해서 변환된 m개의 피쳐와 f0를 더한 m+1개의 피쳐를 통해 가설 h(theta)에 대한 비용함수가 정의된다.
2. 일반화에서, n은 m이되며, 0번째 세타는 제외된다.
3. 원래대로라면 세타의 놈의 제곱갑을 최소화 하는 것이지만, 커널을 통하여 약간 변형되어 벡터 M이 사이에 들어가게 된다.

1. 뭐 앞의 것들은 잊어 먹어도 상관이 없지만, 실지로 SVM을 돌리는데 필요한 파라미터는 기억을 해둬야 한다.
2. 먼저 상수 C는 가중치로서, 람다의 역할을 한다.
람다가 작으면 C는 커지게되고,
즉, 트레인 데이터에 대한 설명력이 강해진다. 선입관은 작아지며, 트레인 데이터에 대한 포용력이 강해진다.
람다가 크면 C는 작아지게 된다.
즉, 트레인 데이터에 대한 설명력이 약하다, 즉 선입관이 높아지게 되기 때문에, 트레인 데이터에 대한 포용력이 약하다.
3. 시그마 제곱, 분산의 경우 일종의 컨버터 역할을 하기 때문에 커널 사용의 중요한 변수다. 분산이 크면, 값들도 뚜렷하게 구분되지 않는다. 그로 인해서, 일종의 이것도 선입관으로 보는 것인가? 어쨌든 그로인해서 트레인 데이터에 대한 설명력은 약해진다.
시그마 제곱이 작을 경우, 극단적으로 값을 변환하게 되고 그로 인해서 트레인 데이터의 구분이 잘되고, 트레인 데이터에 대한 설명력 증가된다.
'2019년 혁신성장 청년인재 집중양성(빅데이터) > [COURSERA] Machine Learning Stanford Uni' 카테고리의 다른 글
| [week8] Clustering (0) | 2019.11.03 |
|---|---|
| [week7] SVMs in Practice (0) | 2019.10.28 |
| [Week7] Large Margin Classfication (0) | 2019.10.28 |
| [week6] Handling Skewed Data (0) | 2019.10.11 |
| [week6] Building a Spam Clasifier (0) | 2019.10.10 |



