part 4
1. 데이터 베이스의 관계를 표현하고 데이터베이스 정규화를 나타내는 방법에 대해서 배운다.
2. 제 3정규형에는 많은 이론이 있다.
3. 간단하게 설명하면, 중복된 문자열을 사용하지 않으며, 문자열 대신, 다른 정수 값을 이용하는 것이다.
4. 즉 반복되는 문자열에 대해서 테이블을 만들고, 각 행에 정수를 배정한 뒤, 그 정수를 이용해 행을 다른 곳으로 가리키게 한다.
5.이 키로 구성된 특별한 열을 각 표에 추가한다. 간단하지만 이렇게 하면 제 3정규형이 된다.
*데이터 정규화에 대해서는 한 번 정리를 해야할 것 같다.

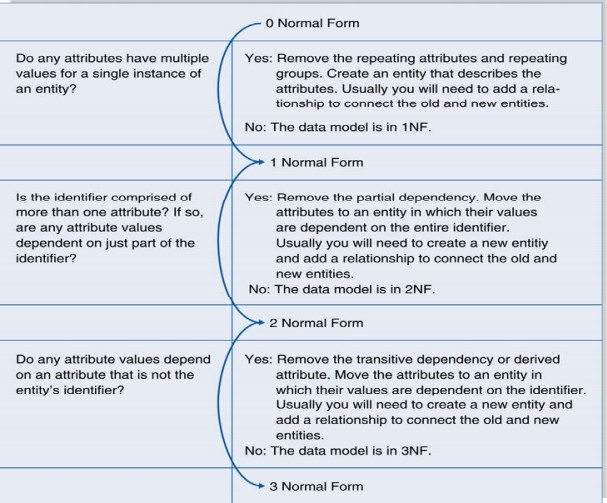
6. 중복되지 않은 어떤 값을 가리키는 것을 프라이머리 키라고 한다.
7. 작은 키를 이용해서, 그런 키들을 가리키는 포인터를 이용해서 데이터의 관계를 모델링 하는 것이 핵심이다.

8. 세 종류의 키가 있다.
9. 프라이머리 키는 일반적으로 정수, 자동으로 증가하는 필드
10. 논리 키 사람들이 사용하는 일반적인 키 (인간이 간단히 알아봄)
11. 외부키 다른 테이블의 로우를 포인팅하는 정수 키

12. 논리키는 반드시 분리되어야 한다.
13. 정수는 프라이머리키에 사용된다.
14. 왜냐하면 논리키는 바뀔(갱신 될) 수 있기 때문이다.
15. 그래서 밖에서 아무 의미를 가질 수 없도록 작은 정수를 사용해야 한다.

16. 외부키는 다른 표의 행을 가리키고 있다
17. 선생님은 id라는 제목을 프라이머리 키를 가리킬 때 사용한다.
18. 표 이름 맨 앞 글자는 대문자를 사용(Table)
19. 외부키는 테이블_id(table_id)를 써서 테이블의 id를 가리키는 것으로 보여지게 한다.
20. 데이터베이스의 규칙을 이해하는 것이 중요하다.
part 5
1. 필요한 칼럼을 뽑아내는 작업
2. 모든 테이블이 프라이머리 키를 가지고 있고 시작점이 있는 모든 경우
3. 이 작업은 단순한다. 관계를 글로 옮기는 것 뿐이다.
4. 관계형 데이터베이스의 사용은 데이터베이스의 용량을 줄이고 속도를 빠르게한다.
5. 그것이 관계형 데이터 베이스의 핵심이다.
CREATA TABLE Album( id INTEGER NOT NULL PRUMARY KEY AUTOINCREMENT UNIQUE,
artist_id INTEGER,
title TEXT)
6. 용량을 줄여 속도도 높였다.
7. 하지만 어떤 면에서는 반대로 생각해줘야 할 때도 있다.
8. 하지만 이 문제에 대해서 데이터베이스 프로그램은 자동으로 해결해준다.
9. 예를 들자면 이렇다. JOIN은 SELECT 연산의 일부로써 여러개의 테이블을 가로질러 연산한다.
10. 즉 둘 이상의 테이불이서 만족하는 데이터를 추출 하고 싶을 떄 사용한다.
11. JOIN 절에서 ON을 빼면 가능한 모든 조합의 개수를 보여준다.
12. ON은 WHERE절 처럼 조건을 주어, 모든 조합을 계산한 뒤 조건에 맞는 값만을 택하여 보여준다.
13. 어찌보면 비효율적인 것처럼 보여지지만, 그렇지 않다.
14. 이게 추상화의 아름다움이며, SQL의 아름다움이다.
실습
아이튠즈의 libray.xml을 이용하여, 자신의 라이브러리를 데이터 베이스화 시키는 것이 목표다.
1. XML파일을 열고, sqlite와의 연결고리인 trackdb.sqlite를 생성한 후, 파일과 커서로 연결한다.
import xml.etree.ElementTree as ET #XML을 읽어야 하고
import sqlite3 # 데이터 베이스와 소통해야하니 SQLLITE3를 불러옵니다.
conn = sqlite3.connect('trackdb.sqlite') #trackdb.sqlite 커넥트를 생성하고
cur = conn.cursor() #핸들인 커서를 생성합니다.
2. 커서를 통해 테이블을 생성한다.
# Make some fresh tables using executescript(), 새로운 테이블 사용을 위해 지워버리 '''는 아래가 긴 문자열이 되는 것.
#이하 새로운 테이블 생성
cur.executescript('''
DROP TABLE IF EXISTS Artist;
DROP TABLE IF EXISTS Album;
DROP TABLE IF EXISTS Track;
CREATE TABLE Artist (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
name TEXT UNIQUE
);
CREATE TABLE Album (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
artist_id INTEGER,
title TEXT UNIQUE
);
CREATE TABLE Track (
id INTEGER NOT NULL PRIMARY KEY
AUTOINCREMENT UNIQUE,
title TEXT UNIQUE,
album_id INTEGER,
len INTEGER, rating INTEGER, count INTEGER
);
''')
3. 이 부분을 이해하기가 가장 힘들었다. xml파일을 입력하는 부분, 그리고 lookup이라는 함수를 이용하여 xml내의 원하는 속성 값을 찾을 수 있도록 한다.
# 아무것도 입력하지 않으면 Libaray.xml파일이 입력 됨
fname = input('Enter file name: ')
if ( len(fname) < 1 ) : fname = 'Library.xml'
# <key>Track ID</key><integer>369</integer>
# <key>Name</key><string>Another One Bites The Dust</string>
# <key>Artist</key><string>Queen</string>
def lookup(d, key): # 객체의 키가 객체 안에 있다. 그렇기 때문에 모든 자식에 걸쳐 반복문을 실행해야 한다.
found = False # found = False로 지정하는 이유가 뭘까?
for child in d: # d의 원소 child에 대해서 반복문을 시행한다.
if found : return child.text # 여기도 무너 듯인지.
if child.tag == 'key' and child.text == key : #child의 tag가 'key'이고 child의 text가 우리가 찾고 있는 특성 key라면
found = True # found = True다. 우리가 찾고 있는 태그와, 태그의 값(속성)이 맞는 것만을 찾기 위해서, found를 False로 줘야 함.
return None # lookup의 return 값은 None형임.
4. fname을 ET.parse를 통해 파싱을하고, findall을 통해 xml에서 원하는 부분 dict*3 에 해당하는 부분을 선택하고
위에서 정의한 lookup을 통해 각 음악 정보에서 원하는 특성값을 가져온다.
이 코드 블럭 이하로는 모두if의 반복문에 속한다.
# 아래의 모든 것들을 다 살펴보고, lookup, 즉 entry에 대해서 'Name'이라는 키에 대한 값을 name으로. 이하 동문
name = lookup(entry, 'Name')
artist = lookup(entry, 'Artist')
album = lookup(entry, 'Album')
count = lookup(entry, 'Play Count')
rating = lookup(entry, 'Rating')
length = lookup(entry, 'Total Time')
if name is None or artist is None or album is None : #단, 셋 중하나가 없다면 Continue 한다.
continue
print(name, artist, album, count, rating, length)5. 원하는 특성 값에 대해서 각 변수에 넣어준다.
# 아래의 모든 것들을 다 살펴보고, lookup, 즉 entry에 대해서 'Name'이라는 키에 대한 값을 name으로. 이하 동문
name = lookup(entry, 'Name')
artist = lookup(entry, 'Artist')
album = lookup(entry, 'Album')
count = lookup(entry, 'Play Count')
rating = lookup(entry, 'Rating')
length = lookup(entry, 'Total Time')
if name is None or artist is None or album is None : #단, 셋 중하나가 없다면 Continue 한다.
continue
print(name, artist, album, count, rating, length)
6. 특성 값을 찾았으니, 이제 그 값을 각 테이블에 넣어준다. 프라이버리 키와, 외부키를 기억하자.
#INSERT OR IGNORE 이미 들어 있으니, 넣지마라고 하는 것과 같다.
# Artist 테이블의 name 칼럼에 위에서 찾은 artist를 넣고
cur.execute('''INSERT OR IGNORE INTO Artist (name)
VALUES ( ? )''', ( artist, ) )
# 그 artist 이름이 name인 곳의 Artist의 id를 선택한 후, 그 값을 artist_id로 한다.
cur.execute('SELECT id FROM Artist WHERE name = ? ', (artist, ))
artist_id = cur.fetchone()[0]
# 위와 같은 방식으로, Album의 title과 artist_id 칼럼에
# 위에서 찾은 album과 artist_id를 넣어주며
cur.execute('''INSERT OR IGNORE INTO Album (title, artist_id)
VALUES ( ?, ? )''', ( album, artist_id ) )
# albumdl Album 테이블의 title과 같은 곳의 id를 택하고, 그 값을 album_id로 할당한다.
cur.execute('SELECT id FROM Album WHERE title = ? ', (album, ))
album_id = cur.fetchone()[0]
7. 마지막으로 Track에 이제까지 만든 모든 테이블 정보를 이용하여 노래 정보를 구성한다.
# Track 테이블에 대해서 각 title, album_id, len, rating, count를 업데이트한다.
cur.execute('''INSERT OR REPLACE INTO Track
(title, album_id, len, rating, count)
VALUES ( ?, ?, ?, ?, ? )''',
( name, album_id, length, rating, count ) )
conn.commit()
'2019년 혁신성장 청년인재 집중양성(빅데이터) > PYTHON 공부 - PY4E' 카테고리의 다른 글
| PY4E - Chapter 13 Twitter API (트위터 API를 이용한 크롤링) (0) | 2019.07.18 |
|---|---|
| PY4E - Chapter 15 Database, Many to many (3) (0) | 2019.07.14 |
| PY4E - Chapter 15 Database (1) (0) | 2019.07.13 |
| PY4E - Chapter 14 Python Objects (0) | 2019.07.10 |
| PY4E - Chapter 13 Web SOA and Service GeoJSON (3) (0) | 2019.07.10 |



