A. learning with large datasets
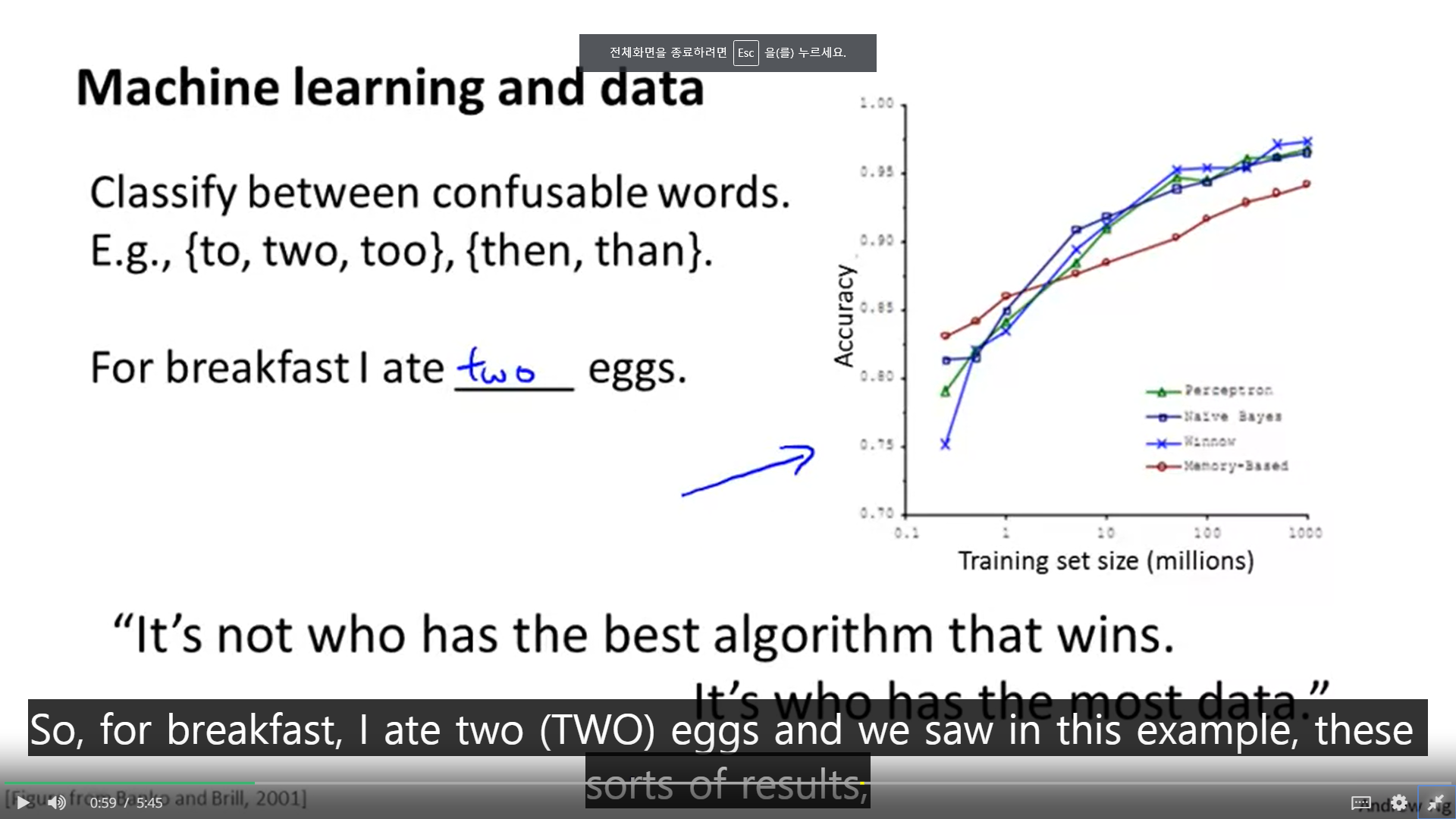
1. 최고의 알고리즘을 가진 사람이 이기는 것이 아니라, 가장 많은 데이터를 가진 사람이 이긴다.
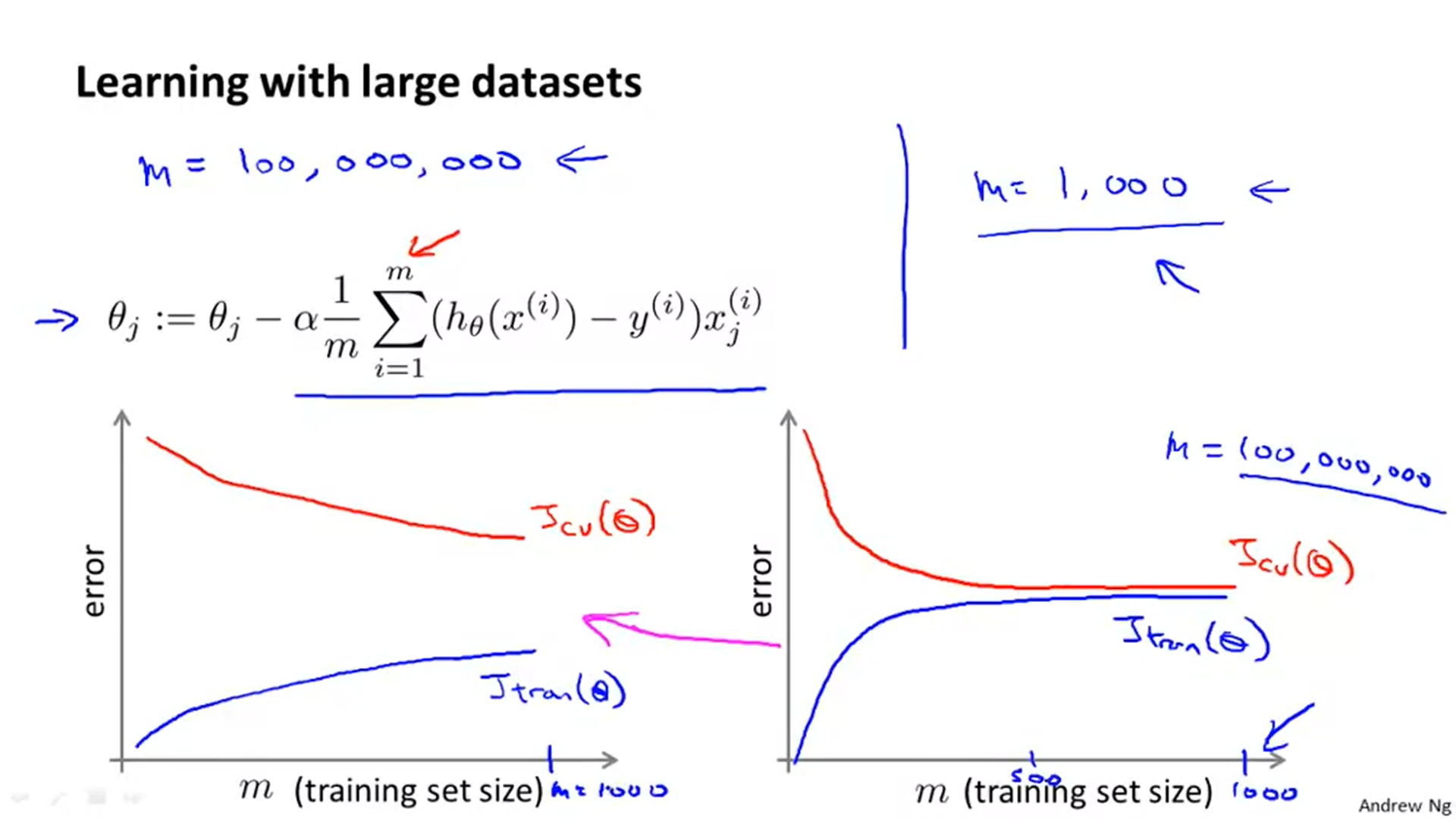
1. 데이터 셋이 많다면, 그 데이터 셋을 모두 다 이용하는 것이 효율적일까? 아니다. 이 때는 Learning Curve를 그려볼 필요가 있다. 왼쪽 그래프와 같이, 트레인에 대한 비용과 검증용 데이터 셋의 비용의 격차가 크다면, 더 많은 양의 데이터 셋으로 실험을 진행하면 되고, 그 격차가 적다면 굳이 더 많은 데이터를 이용할 필요는 없다.
B. Stochastic Gradient Descent

1. Batch gradient descent는 전체 트레인 셋의 비용함수의 평균을 통해 세타를 조절한다. stochastic gradient descent는 매 트레인 샘플 하나마다, 세타를 조절한다. 그러니 지나간 샘플에 적절하도록 세타가 조절되는 것이다. 그러므로, 세타는 순간순간 바뀌 천방지축으로 바뀌어 나간다.
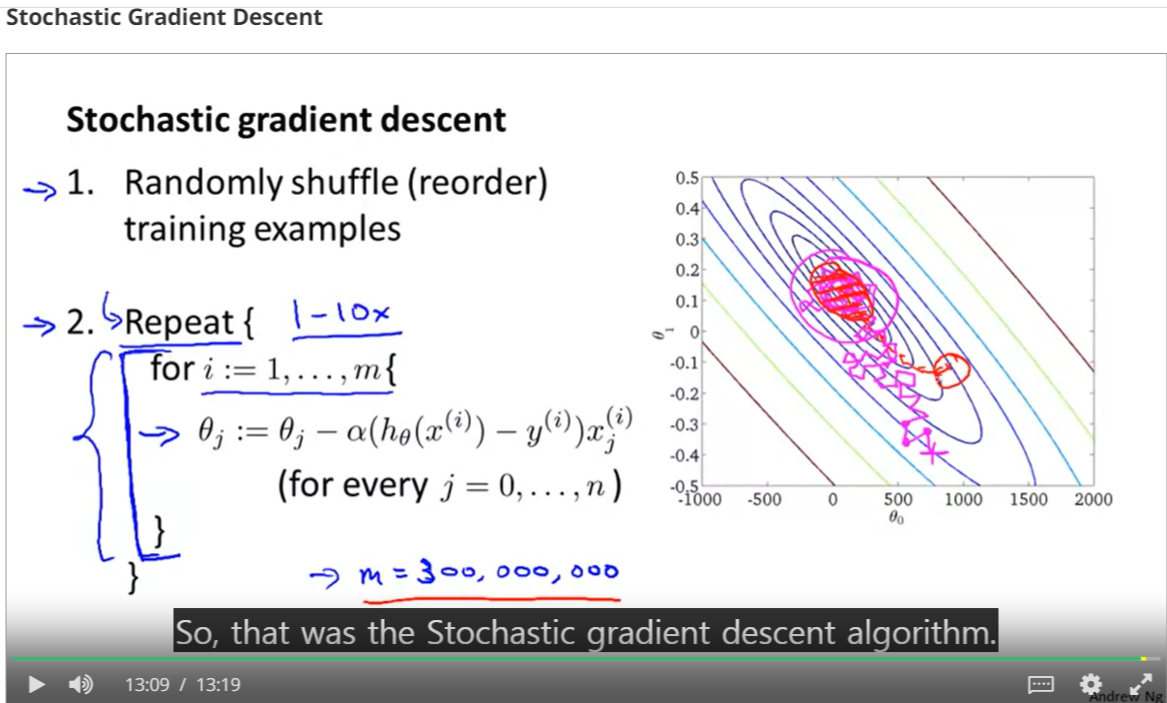
1. 이 방법은 정말, 데이터 셋이 많을 때 사용해야된다. 어중간 하면 그냥 배치 경사하강을 쓰면된다. 배치 경사 항강과 스톸케스틱의 최종 세타는 다를 수는 있지만 근사는 한다고 한다.

1. batch와 stochachsting 의 중간 방법으로 mini batch가 있다. 1개가 아닌 10개와 같이 몇가지의 샘플의 비용함수의 미분을 통해 경사하강을 하는 것이다. 적절한 b를 선택하기만 한다면 둘 보다 빠르게 세타 값을 찾을 수 있을 것이다.
C. Stochastic Gradient Descent Convergence

1. 스톡케스틱 경사하강법을 사용할 때, 굳이 모든 샘플에 대해서 비용함수를 구할 필요는 없다. 예를 들어 마지막 1000개의 샘플의 평균으로 스톡케스틱 경사하강법의 파라미터를 수정할 수 있다.
2. 왼쪽 위의 그래프에서는 파랑선은 1,000개 빨강선은 러닝 레이트를 더 작게 하여 사용한 것으로, 더 완만하고 더 낮은 비용의 결괄를 뽑아낼 수 있었고
3. 오른쪽 위에서는 다른 예시로 더욱 완만 해진 것을 확인 할 수 있었다.
4. 왼쪽 하단에서는 학습을 하지 않는 것처럼 보이는 파랑선에, 샘플 수와, 러닝레이트를 낮춰줌으로써 미약한 효과를 볼 수 있었고
5. 에서는 방산하고 있으므로, 더 낮은 러닝 레이트를 사용해야한다.
'2019년 혁신성장 청년인재 집중양성(빅데이터) > [COURSERA] Machine Learning Stanford Uni' 카테고리의 다른 글
| [week11] Problem Description and Pipeline, Photo OCR(Optical Character Recognition) (0) | 2019.11.16 |
|---|---|
| [week10] online learning (0) | 2019.11.15 |
| [week9] Low Rank Matrux Factorization (0) | 2019.11.08 |
| [week9] Collaborative Filtering (0) | 2019.11.07 |
| [week9] Predicting Movie Rating (0) | 2019.11.07 |



