1. 처음 생각에는 json 파일에서 내가 원하는 컬럼만 뽑아와지 생각을 했다.
import json
with open('bit_kor.json') as json_file : # bit.kor.json을 json_file을 통해 핸들을 만들고
json_data = json.load(json_file) # json_file을 통해 bit.kor.json을 json_data 형태로 로딩
json_txt = json_data["text"] #json_data의 "text" 행렬만을 가져와서
print(json_txt) # 확인하려고 했지만
2. 하지만 되지 않았다.
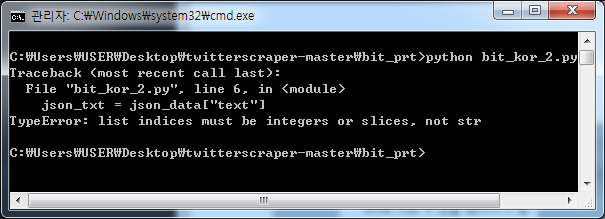
...더보기
TypeError: list indices must be integers or slices, not str
이 에러는 내가 리스트와 딕셔너리의 형태를 이해하지 못한 채, 데이터를 다루려고 했기 때문에 발생한 문제다.
3. json파일이 python위에서 읽혀졌을(read, load) 떄, json파일은 리스트 안의 딕셔너리 형태를 가지게 된다.
그렇기 때문에 json파일 중 특정 컬럼을 읽기 위해선, 그 리스트이 몇 번째 딕셔너리인지 특정해야 한다.
import json
with open('bit_kor.json') as json_file :
json_data = json.load(json_file)
json_txt = json_data[0]["text"]
print(json_txt)
예를 들어, 위와 같이 json_data의 0번째 원소의 ["text"]라는 레이블을 가진 값을 가져오라고 해야
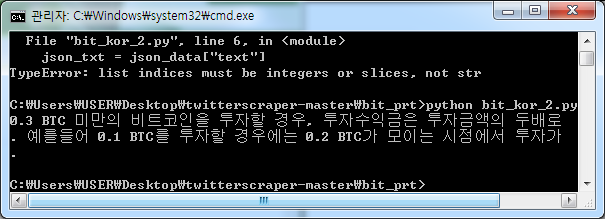
이렇게 값을 얻을 수 있다.
하지만 이래서야 한 원소의 "text" 값 밖에 얻을 수 없기 때문에 반복문을 넣어 줘야 한다.
import json
with open('bit_kor.json') as json_file :
json_data = json.load(json_file)
#json_txt = json_data[0]["text"]
#print(json_txt)
for i in json_data :
json_txt = i['text']
print(json_txt)
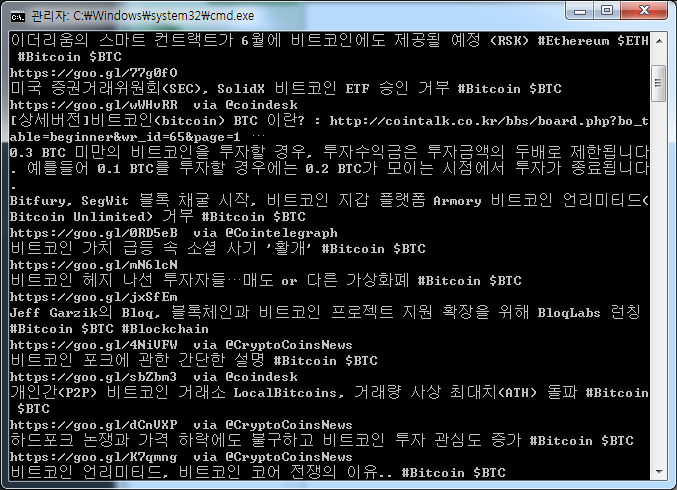
4. 하지만 위에 것은 반복문을 시행하여 txt를 본 것일 뿐이다. 텍스만을 가지고 있는 리스트를 만들기 위해서는 append를 반복문에 추가해야 한다.
import json
with open('bit_kor.json') as json_file :
json_data = json.load(json_file)
#json_txt = json_data[0]["text"]
#print(json_txt)
list = [] # 리스트 생성
for i in json_data :
json_txt = list.append(i['text']) #list에 i번 원소 'text'를 추가
print(lsit) # list 출력
5. 이거 다 집어 치우고, 그냥 판다스 데이터 프레임 형태로 받아서, 판다스 데이터 프레임을 다루는 것이 더 쉽다.
import json
import pandas as pd
with open('bit_kor.json') as json_file : # bit_kor.json파일에 json_file이라는 핸들을 만들고
json_data = json_file.read() # 그 파일을 읽어들여 json_data로 저장
bit_json = json.loads(json_data) # json_data를 json.loads를 하여 딕셔너리 형태로 받아오며
#print(bit_json) #작동 확인
bit_json_df = pd.DataFrame(bit_json, columns=['text']) # bit_json의 'text'컬럼을 pd.datafram형태로 저장
#print(bit_json_df) # 확인
bit_json_df.to_csv("bit_kor.csv", mode='w')# bit_kor.csv라는 이름으로 저장솔직히 이게 훨씬 쉬워 보인다. 속도 차이는 확인은 안 해봤다.
'2019년 혁신성장 청년인재 집중양성(빅데이터) > STACKOVERFLOW 1일 1질문' 카테고리의 다른 글
| normalization, standardization의 차이는 무엇일까? (0) | 2019.07.15 |
|---|---|
| 다섯 번째 질문. Difference Between One-to-Many, Many-to-One and Many-to-Many? (0) | 2019.07.14 |
| 네 번째 질문. what is the true difference between lemmatization vs stemming? (0) | 2019.07.12 |
| 두 번째 질문. parameter(매개변수)와 argument(인자)의 차이가 뭔가요? (0) | 2019.07.10 |
| 첫 번째 질문. VOID FUNCTION과 FRUITFUL FUNCTION의 차이가 뭐에요? (0) | 2019.07.06 |
