|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
|
drive.mount('/content/drive')
import pandas as pd
import numpy as np
train = pd.read_csv("/content/drive/My Drive/BIGCOIN/PREPORCOESSING/트레인데이터/merge_train_reset.csv")
from sklearn.pipeline import Pipeline
# 튜토리얼과 다르게 파라메터 값을 수정
# 파라메터 값만 수정해도 캐글 스코어 차이가 많이 남
#CountVectorizer 모델을 생성, Parameter 수정으로 1차 재료를 바꿀 수 있음
vectorizer = CountVectorizer(analyzer = 'word',
tokenizer = None,
preprocessor = None,
stop_words = None,
min_df = 2, # 토큰이 나타날 최소 문서 개수
ngram_range=(1, 3),
max_features = 20000
)
vectorizer
# 파이프라인은 값을 반복하여 넘겨주는 역할을 하는 것처럼 보임
pipeline = Pipeline([
('vect', vectorizer),
])
# train_test_split을 이용하여 train데이터를 train과 test로 나눠 줌.
from sklearn.model_selection import train_test_split
X_train, X_test = train_test_split(train, test_size=0.2, random_state=123)
#train과 test의 텍스트를 one-hot-vector화 시킴
#처음에는 features 데이터를 다시 train 데이터프레임에 넣은 다음에 다음 과정을 진행했다. 하지만, 이 과정에서 생성된 매트릭스가 사이킷런 전용인 같다?
%time X_train_data_features = pipeline.fit_transform(X_train["tweet"])
X_train_data_features
%time X_test_data_features = pipeline.fit_transform(X_test["tweet"])
X_test_data_features
#렌덤 포레스트 분류기 생성
from sklearn.ensemble import RandomForestClassifier
# 랜덤포레스트 분류기를 사용
forest = RandomForestClassifier(
n_estimators = 100, n_jobs = -1, random_state=2018)
forest
#X_train_data_features를 X_train['sent_score']로 교육
# 교차 검증을 하여 'acuuracy'로 점수를 계산
# 처음에는 scoring응 'roc auc'를 통해 계산하려고 했지만 roc auc는 바이너리 클래스의 측정만 가능하다.
from sklearn.model_selection import cross_val_score
%time score = np.mean(cross_val_score(\
forest, X_train_data_features, \
X_train['sent_score'], cv=5, scoring='accuracy'))
score
# 생성된 forest 모델을 이용하여 test_data_features를 예측하여 result에 저장
result = forest.predict(test_data_features)
result[:10]
# 비교를 위해 result(예측)의 sent_score와 X_test의 sent_score를 모아 데이터 프레임 위에 놓음
output = pd.DataFrame(data={'id':X_test['Unnamed: 0'], 'sentiment':result, 'sent_score' : X_test['sent_score']})
# 숫자로 확인
output_sentiment = output['sentiment'].value_counts()
output_sentiment
#그림으로 테스트의 예측값과 본래 값을 비교.
import matplotlib.pylab as plt
import seaborn as sns
fig, axes = plt.subplots(ncols=2)
fig.set_size_inches(12,5)
sns.countplot(X_test['sent_score'], ax=axes[0])
sns.countplot(output['sentiment'], ax=axes[1])
http://colorscripter.com/info#e" target="_blank" style="color:#4f4f4ftext-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |

1. 왼쪽이 원래 test의 sentiment이고 오른 쪽이 예측한 sentiment의 수이다.
2. 결과를 뭐 자세하게 해석할 필요는 없겠지만, 문제는 애초에 중립 값이 너무 많았다는 점...이 영향이 크지 않았나 싶다.
3. 중립 값이 너무 많으니 편향되어 학습되었을 것이고, 긍정에 태깅되어 있던 애들 대부분이 중립으로 예측되었다.
4. 흠...그래도 너무한 것 아닌가. 중립보다 긍정으로 태깅이 더 많이 되어 있었다면, 긍정으로 더 많이 태깅 되어야 하는 것 아닐까?
5. 아니면 train에서의 score의 양에서 편향이 되어 있을까?
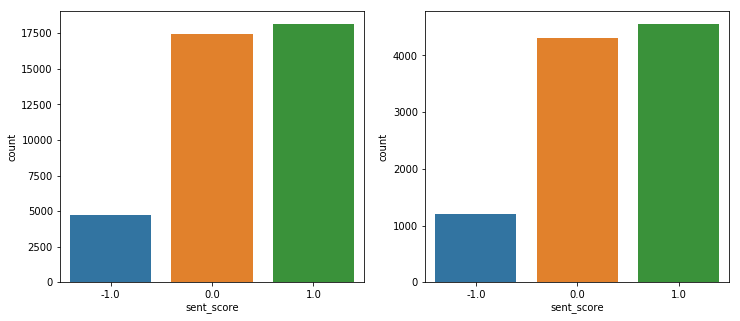
1. X_train과 X_test의 score는 거의 일정하게 분류 된 것으로 보인다..
'2019년 혁신성장 청년인재 집중양성(빅데이터) > 집중양성과정 프로젝트 01' 카테고리의 다른 글
| [비트코인 전처리2] 트윗 데이터에 가격 태그 붙이기 (0) | 2019.09.16 |
|---|---|
| [비트코인 트위터 감성분석] 1년 간 트위에서 시간당 100개씩 트윗 산출[1] (0) | 2019.09.15 |
| [비트코인 감성분석 프로젝트] 트레인 데이터 전처리 (2) (0) | 2019.09.06 |
| [기계학습을 위한 데이터 전처리] 시간단위를 잘못 계산해서, 처음 부터 다시해야 한다는 sull. (0) | 2019.09.05 |
| [20190903] 기계학습을 위한 사전 전처리 (0) | 2019.09.03 |

