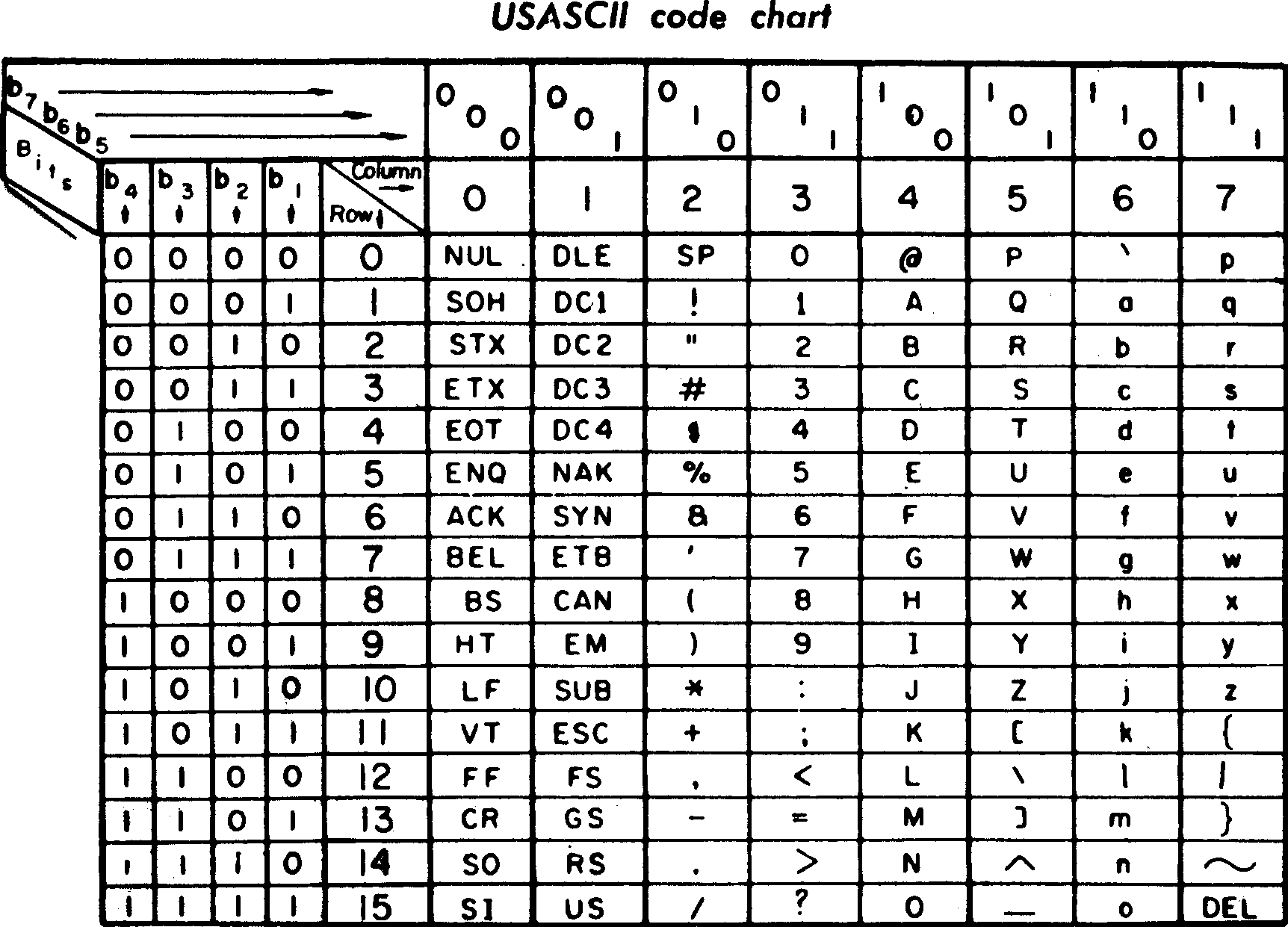
1.ASCII : American Standard Code for information interchange
2. 아주 가벼운 문자. 128가지
3. 8비트, 1바이트
4. 파이썬에서 ord()를 쓰면 숫자 값을 알 수 있음
5. 시대가 복잡해지고, 사용하는 문자가 많아졌다. 아식의 한계 도달.
6. 괴장히 복잡, 무거운 유니코드까지 발전. 엄청나게 넓은 공간을 가지고 있다. 어떤 문자라도 저장이 가능하다.
7. 다만 문제는 유니코드를 네트워크로 전송할 때 용량이 과도하게 크다는 것이다.
8. UTF32는 유니코드와 거의 같으며, UTF16은 압축형이다.
9. UTF8은 1~4 바이트로 동적 변경이 가능하다.
10. UTF8이 짱이다. 굉장히 멋있다.

11. 파이썬 3의 가장 큰 특징은 문자열을 유니코드와 같게 만든 것이다.
12. 파이썬 3에는 바이트 객체가 있다. 즉 객체의 배열이다. (?)
13. 파이썬2에서는 바이트와 문자열이 같다. 그리고 유니코드는 이상한 것이었다.
14. 하지만 파이썬3에서는 문자열과 유니코드가 같고, 바이트코드가 이상한 것이다.
15. 파이썬 3에서는 모든 문자열은 유니코드이므로 프로그램 내부에서 파일을 읽거나 작업하는데 무리가 없다.
16. 그렇지만 외부 소켓과 소통 할때, 데이터 형식은 꼭 알고 있어야 한다.
17. 데이터를 받았다면, 해석하거나 올바르게 디코딩해주어야 한다.
18. 현재의 네트워크는 대부분 UTF8를 사용한다.
19. 인코딩과 디코딩을 통해 번역을 해주어야 한다.
20. 소캣은 이런 작업이 일어난 장소다.


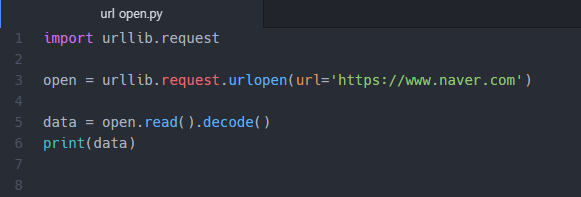
21. urllib은 연결도 만들고, get요청을 인코딩하고 응답도 가져오며, 모든 헤더를 받아와 저장합니다.
22. 하지만 헤더의 내용은 보지 않고, 바로 객체로 반환합니다.
23. 한번에 모든 파일을 읽어내고 문자열들이 바이트로 들어오게 됩네다.
24. 헤더가 보이지 않지만, 방법이 있습니다.
'2019년 혁신성장 청년인재 집중양성(빅데이터) > PYTHON 공부 - PY4E' 카테고리의 다른 글
| PY4E - Chapter 13 Web Service JSON (2) (0) | 2019.07.10 |
|---|---|
| PY4E - Chapter 12 Unicode and UTF-8 in Python (3) (0) | 2019.07.09 |
| PY4E - Chapter 12 Unicode and UTF-8 in Python (1) (0) | 2019.07.09 |
| PY4E: Chapter 11 Regular Expressions (0) | 2019.07.09 |
| PY4E: Chapter 9 Dictionaries (0) | 2019.07.08 |



