A. 복습
1. 리스트는 제너릭 벡터라고도 한다.
2. R은 문자열을 표시하는 경우가 아니라면 ""에 민감하지 않다.
B. 데이터 프레임
1. 인덱싱
벡터 이름으로 데이터 프레임에서 ID라는 이름으로 인덱싱 하는 두가지 방법이다.
하나는 데이터 프레임 형태로 나오게 되고
dataframe_ex["ID"]
ID
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
10 10
하나는 벡터 형태로 나오게 된다
> dataframe_ex$ID
[1] 1 2 3 4 5 6 7 8 9 10
2. 구조 보기
2-1. str
str(dataframe_ex)
'data.frame': 10 obs. of 4 variables:
$ ID : int 1 2 3 4 5 6 7 8 9 10
$ SEX : Factor w/ 2 levels "F","M": 1 2 1 2 1 2 1 2 1 2
$ AGE : num 50 40 20 23 52 6 5 46 4 5
$ AREA: Factor w/ 5 levels "경기","광주",..: 5 3 1 4 2 5 3 1 4 2
2-2. summary
summary(dataframe_ex)
ID SEX AGE AREA
Min. : 1.00 F:5 Min. : 4.00 경기:2
1st Qu.: 3.25 M:5 1st Qu.: 5.25 광주:2
Median : 5.50 Median :21.50 대전:2
Mean : 5.50 Mean :25.10 부산:2
3rd Qu.: 7.75 3rd Qu.:44.50 서울:2
Max. :10.00 Max. :52.00 2-3. as.character
> dataframe_ex$ID <- as.character(dataframe_ex$ID)
> summary(dataframe_ex)
ID SEX AGE AREA
Length:10 F:5 Min. : 4.00 경기:2
Class :character M:5 1st Qu.: 5.25 광주:2
Mode :character Median :21.50 대전:2
Mean :25.10 부산:2
3rd Qu.:44.50 서울:2
Max. :52.00
2-4. 리스트와 데이터프레임의 차이
리스트와 공통적인 것은 다른 형식의 모임이지만 데이터 프레임은 그 길이가 같다.
데이터 프레임의 "소속"은 데이터프레임이다
> class(dataframe_ex)
[1] "data.frame"
데이터 프레임은 벡터로 이루어져 있지만, 처리 단위는 list이다.
> typeof(dataframe_ex)
[1] "list"
2-5.리스트와 데이터프레임의 차이
> list1 <- list(ID, SEX, AGE, AREA)
> list1
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10
[[2]]
[1] "F" "M" "F" "M" "F" "M" "F" "M" "F" "M"
[[3]]
[1] 50 40 20 23 52 6 5 46 4 5
[[4]]
[1] "서울" "대전" "경기" "부산" "광주" "서울" "대전"
[8] "경기" "부산" "광주"
> class(list1)
[1] "list"
> typeof(list1)
[1] "list"2-6. head
> head(mtcars)
mpg cyl disp hp drat wt qsec
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02
Datsun 710 22.8 4 108 93 3.85 2.320 18.61
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02
Valiant 18.1 6 225 105 2.76 3.460 20.22
vs am gear carb
Mazda RX4 0 1 4 4
Mazda RX4 Wag 0 1 4 4
Datsun 710 1 1 4 1
Hornet 4 Drive 1 0 3 1
Hornet Sportabout 0 0 3 2
Valiant 1 0 3 1
> head(mtcars, 3)
mpg cyl disp hp drat wt qsec vs
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1
am gear carb
Mazda RX4 1 4 4
Mazda RX4 Wag 1 4 4
Datsun 710 1 4 1
3. mean 에 필요한것은 벡터이지 리스트가 아니다.
> mean(mtcars2$mpg)
[1] 20.09062
> mean(mtcars2["mpg"])
[1] NA
Warning message:
In mean.default(mtcars2["mpg"]) :
인자가 수치형 또는 논리형이 아니므로 NA를 반환합니다
> mean(mtcars2$mpg)
[1] 20.09062
> mean(dataframe_ex[["AGE"]])
[1] 25.1
4. 클래스는 객체 개념으로 답을 준다.
> typeof(gender)
[1] "character"
> str(gender)
chr [1:6] "M" "F" "F" "F" "M" "M"
typeof(gender)
[1] "integer"
클래스는 객체 개념으로 답을 준다.
> class(gender)
[1] "factor"
5. 그래프를 만들 때에는 타입을 확인해야 한다.
5-1. 히스토그램 hist(vector) ?hist로 알아보고 쓸 것!
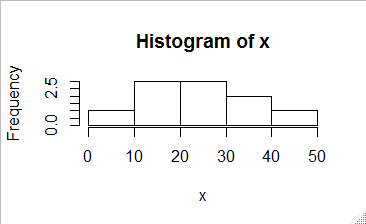
> hist(dataframe_ex$AGE, xlim = c(0,60), xlab = "나이", ylab="명수", col=rainbow(length(dataframe_ex$AGE)) )
6. rbind, cbind in data.frame, 되도록 이면 데이터 프레임의 형태로 rbind를 시켜줘야 한다.
> str(a)
'data.frame': 2 obs. of 4 variables:
$ 성명 : Factor w/ 2 levels "손오공","홍길동": 2 1
$ 나이 : num 20 30
$ 주소 : Factor w/ 2 levels "부산","서울": 2 1
데이터 프레임에 열과 행을 추가할 때, 벡터로 추가를 할 수 있으나 잘못하면
> a<- rbind(a, c("장발장", 40, "파리","행정"))
아래와 같이 나가이 문자로 바뀔 수 있다.
> str(a)
'data.frame': 5 obs. of 4 variables:
$ 성명: Factor w/ 3 levels "손오공","홍길동",..: 2 1 3 3 3
$ 나이: chr "20" "30" "40" "40" ...
$ 주소: Factor w/ 3 levels "부산","서울",..: 2 1 3 3 3
$ 학과: Factor w/ 3 levels "e-비즈","경영",..: 1 2 3 3 3
하지만 리스트를 삽입한다면 OK!
> a<- rbind(a, list("장발장", 40, "파리","행정"))
데이터 프레임의 리스트의 타입을 바꿔 준 뒤에 새로운 행을 삽입해야 한다. 항상 삽입되는 것과 삽입 되어지는 것의
타입을 고려해야 한다.
a$성명 <- as.character(a$성명)
a$주소 <- as.character(a$주소)
a$학과 <- as.character(a$학과)
7.
> z[1]
성명
1 홍길동
2 손오공
3 장발장
> z["성명"]
성명
1 홍길동
2 손오공
3 장발장
> z$성명
[1] "홍길동" "손오공" "장발장"
> z[[1]]
[1] "홍길동" "손오공" "장발장"
z[1]은 리스트다. 리스트가 하나 밖에 없기 때문에 리스트 중의 첫번째니 리스트가 나온다.
> z[1][1]
성명
1 홍길동
2 손오공
3 장발장
백터들 중에 첫번째를 고르라는 것, 벡터가 나온다.
> z[[1]][1]
[1] "홍길동"
C. 파일 읽기
1.
Working Directory 찾기
getwd()
list1 이 "mycar.rda"로 저장된다.
save(list1, file = "mycar.rda" )

2. mycars.rda를 로딩하기
load("mycars.rda")

3. csv파일 읽고 저장하기
R로 저장하면 Save이지만, R이외의 형식으로 저장 하는 것은 Wirte가 된다.
quakes 데이터프레임을 qukes.csv로 저장한다
> write.csv(quakes, "quakes.csv")
load와는 다르게 read할 때에는 변수에 저장을 해주어야 한다.
x <- read.csv("quakes.csv")
read.csv는 텍스트파일도 읽을 수 있다.
x<- read.csv("quakesTableCSV.txt")
read.table로도 읽을 수 있다.
x<- read.table("quakesTableCSV.txt", sep=",")
4. txt파일로 저장하기
write.table(quakes,"quakesTXT.txt")
5.
head 값이 없다면 정해줄 수 있다.
> qu<- read.table("TEST.txt", col.names = c("ID","SEX","AGE","AREA"))xls는 옛날 버전이다. xls는 호환모드로 열리게 된다.
excel의 경위 xls와 xlsx 두가지가 있다. xls, xlsx의 경우 패키지가 필요하다.
install.packages("readxl")
library(readxl)
test <- read_xls("quakes.xls")

6. sink()와 cat()
sink("sink.txt")
cat("화면 상에 출력 됨")
sink()
sink.txt에 화면상에 출력되는 내용이 모두 저장 된다.
***
cmd 명령어
dir로 파일보기
파일 명 입력 시 실행 됨
TEST.txt
type TEST.txt를 쓰면 cmd 창에 띄어짐
type TEST.txt| findstr 서울
|(파이프라인) 뒤에 findstr로 문자를 찾을 수 있음 "서울"
총평 : txt파일은 바로 읽을 수 있으나, 엑셀에서 열릴 수 없다. csv로 저장하면 엑셀에서 열 수 있다. 목적에 따라서 편한데로 저장할 것.
'2019년 혁신성장 청년인재 집중양성(빅데이터) > [프로그래밍] R' 카테고리의 다른 글
| [프로그래밍,2019/08/27] R 이제까지 했던 것 복습과 바플랏 (0) | 2019.08.27 |
|---|---|
| [프로그래밍 R][2019/08/26] 조건문, 데이터 가공 dplyr (0) | 2019.08.26 |
| [프로그래밍] 20190820, R 데이터 종류() (0) | 2019.08.20 |
| 2019/08/13 R 1 (0) | 2019.08.13 |



